
😀 Profile
I am now a master student of Information and Communication Engineering at the University of Science and Technology of China, pursuing my master’s degree in the School of Information Science and Technology, University of Science and Technology of China. Before this, I graduated from School of College of Information Science and Engineering, Hohai University with a bachelor’s degree.
My research interests include visual content generation, multimedia understand and alignment.
📖 Educations
- 2023.09 - Now, University of Science and Technology of China, Heifei, (GPA: 3.92/4.0, rank: 5/112).
- 2019.09 - 2023.06, Hohai University, Nanjing, (GPA: 4.96/5.0, rank: 1/125).
💻 Internships
- 2023.01 - 2023.06, Alibaba, Quark Search Department, Hangzhou.
📃 Papers

SmartEraser: Remove Anything from Images using Masked-Region Guidance
Longtao Jiang, Zhendong Wang, Jianming Bao, Wengang Zhou, Dong Chen, Houqiang Li
- In this work, we introduce SmartEraser, built with a new ``{removing}” paradigm called Masked-Region Guidance.
- The paradigm guides the model to accurately identify the object to be removed, preventing its regeneration in the output.
- Since the user mask often extends beyond the object itself, it aids in preserving the surrounding context in the final result.
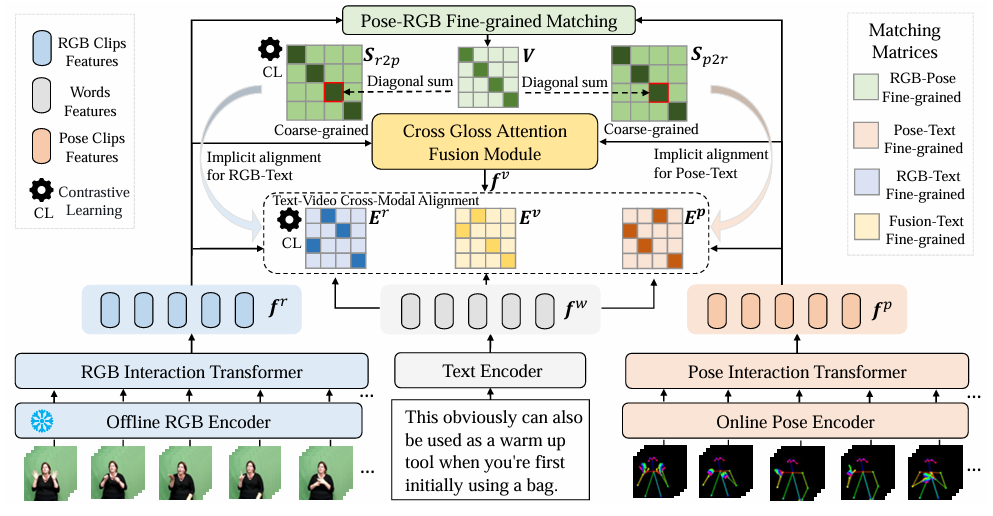
SEDS: Semantically Enhanced Dual-Stream Encoder for Sign Language Retrieval
Longtao Jiang, Min Wang, Zecheng Li, Yao Fang, Wengang Zhou, Houqiang Li
- propose a novel representation framework called Semantically Enhanced Dual-Stream Encoder (SEDS), which aggregates Pose and RGB modalities to represent local and global information of sign language videos.
- The aggregated clip-level video features are then fed into the CLIP vision encoder for interaction, and matched with the word-level text features embedded using the CLIP text encoder.
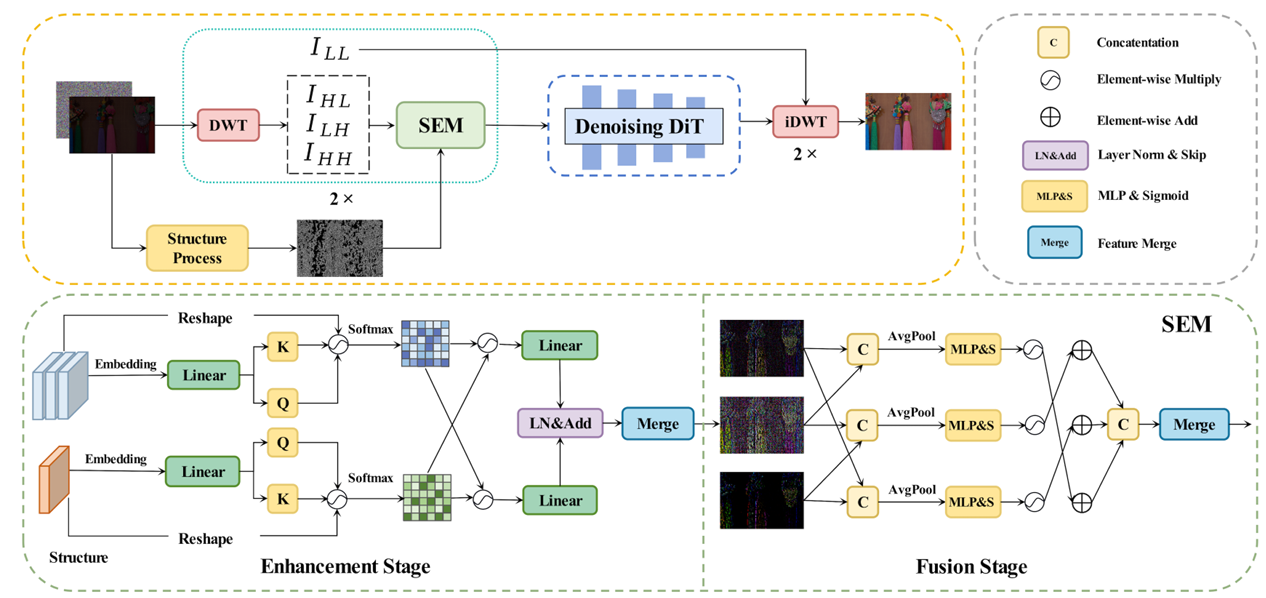
Structure-guided Diffusion Transformer for Low-Light Image Enhancement
Xiangchen Yin, Zhenda Yu, Longtao Jiang, Xin Gao, Xiao Sun, Zhi Liu, Xun Yang
- we firstly introduce DiT into the low-light enhancement task and design a novel Structure-guided Diffusion Transformer based Low-light image enhancement (SDTL) framework.
- Extensive qualitative and quantitative experiments demonstrate that our method achieves SOTA performance on several popular datasets, validating the effectiveness of SDTL.
🔍 Projects
Pre-Training of Web Page Understanding Based on Document Multimodal Large Language Model
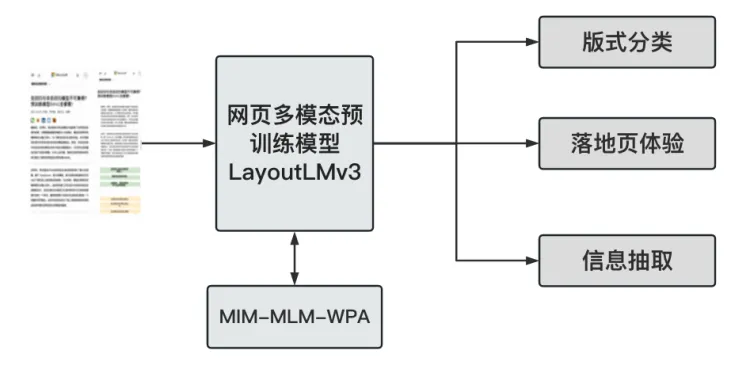
In recent years, a series of document pre training models represented by Microsoft LayoutLM have also achieved significant results in document understanding tasks.The Quark Vertical Innovation Team is responsible for solving the problem of document multimodal understanding in library type documents and web-based documents. The task of understanding web-based documents includes layout classification, page experience, semantic segmentation, node extraction, etc; The task of understanding library type documents includes layout classification, layout experience, domain categories, title extraction, etc. The two are very similar in terms of multimodal model structure and downstream analysis and understanding tasks.
📝 Academic Services
- Conference on Computer Vision and Pattern Recognition (CVPR) 2025, Reviewer
- ACM International Conference on Multimedia (ACM MM) 2024, Reviewer
- Conference on Neural Information Processing Systems (NeurIPS) 2024, Reviewer
🏅 Honors
- 2024.12, HuaWei Scholarship from USTC
- 2023.12, First Class Master’s Scholarship from USTC
- 2023.09, Outstanding Graduate of Hohai University (Top 1%)
- 2023.02, Xiaomi Scholarship Special Prize (Top 1%)
- 2022.10, First Prize of Yan Kai Scholarship (Top 1%)
- 2020.09, National Scholarship for Undergraduate Student (Top 1%)
- 2020.12, Excellent Student Model in Hohai University
- 2020.09, The First Prize Scholarship in Hohai University
🏆 Competitions
- 2022.12, National Second Prize in the National College Student Electronic Design Competition.
- 2022.09, Blue Bridge Cup Software Design Competition National Third Prize.
- 2021.09, Third Prize in the National College Student Intelligent Car Competition.